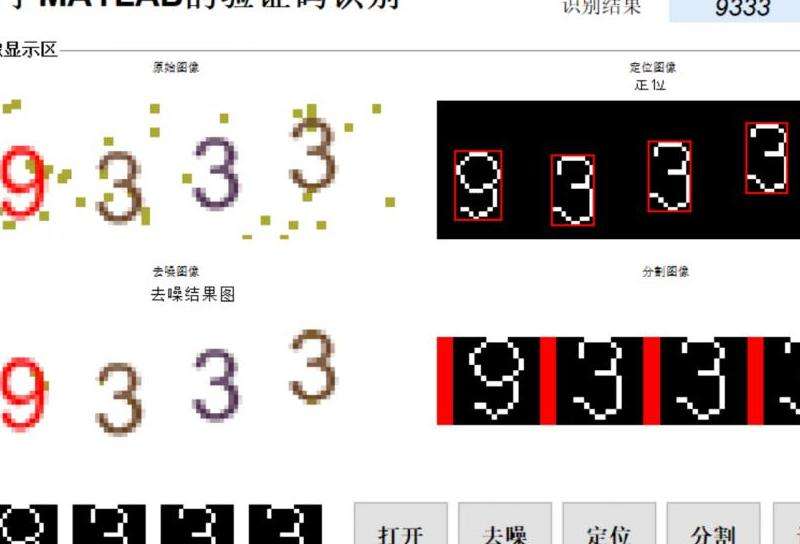
倾斜文字验证码识别技术简介
倾斜文字验证码是一种常见的验证码形式,主要通过将文字进行不同角度的倾斜变换来增加识别难度,防止机器自动识别。解析倾斜文本形式验证码是指通过图像处理和机器学习等技术手段,对倾斜的验证码图像进行预处理和特征提取,然后使用分类算法或深度学习模型进行识别和解析。下面将详细介绍倾斜文字验证码识别的技术。
1. 图像预处理
图像预处理是倾斜文字验证码识别的第一步,其主要目的是去除噪声、平滑图像、调整图像大小和灰度化等。常见的图像预处理技术包括:
- 图像去噪:通过滤波算法(如中值滤波、高斯滤波)或形态学处理(如开运算、闭运算)来去除噪声。

- 图像平滑:使用平滑滤波器(如均值滤波、高斯滤波)来减少图像的细节信息,使图像更加平滑。
- 图像调整:调整图像大小和比例,使其适应后续的特征提取和分类算法。
- 灰度化:将彩色图像转换为灰度图像,减少处理的复杂性。
2. 角度检测和矫正
倾斜文字验证码中,文字可能以不同的角度倾斜,因此需要对验证码图像进行角度检测和矫正。主要的方法包括:
- 边缘检测:通过边缘检测算法(如Sobel算子、Canny算子)来检测图像中的边缘信息。
- 直线检测:使用Hough变换等方法来检测图像中的直线,从而得到文字倾斜的角度。
- 角度矫正:利用旋转、仿射变换等方法将倾斜的验证码图像矫正为水平方向,便于后续的特征提取和分类算法。
3. 特征提取
特征提取是倾斜文字验证码识别的核心步骤,其目的是从经过预处理和矫正的图像中提取出具有鉴别性的特征。常见的特征提取方法包括:
- 统计特征:如图像的平均灰度、方差、梯度直方图等。
- 文字特征:如文字轮廓、笔画宽度、连通域数目等。
- 纹理特征:如局部二值模式(LBP)、灰度共生矩阵(GLCM)等。
4. 分类算法和深度学习模型
最后一步是使用分类算法或深度学习模型对提取到的特征进行识别和解析。常见的分类算法包括支持向量机(SVM)、K最近邻(KNN)等,而深度学习模型如卷积神经网络(CNN)在倾斜文字验证码识别中也取得了较好的效果。
倾斜文字验证码识别是一个复杂而具有挑战性的任务,需要综合运用图像处理、特征提取和分类算法等技术。随着深度学习的发展,利用深度学习模型对倾斜文字验证码进行识别的研究也取得了显著的进展。未来,倾斜文字验证码识别技术将进一步提高准确率和鲁棒性,为验证码的自动识别和解析提供更多的可能性。